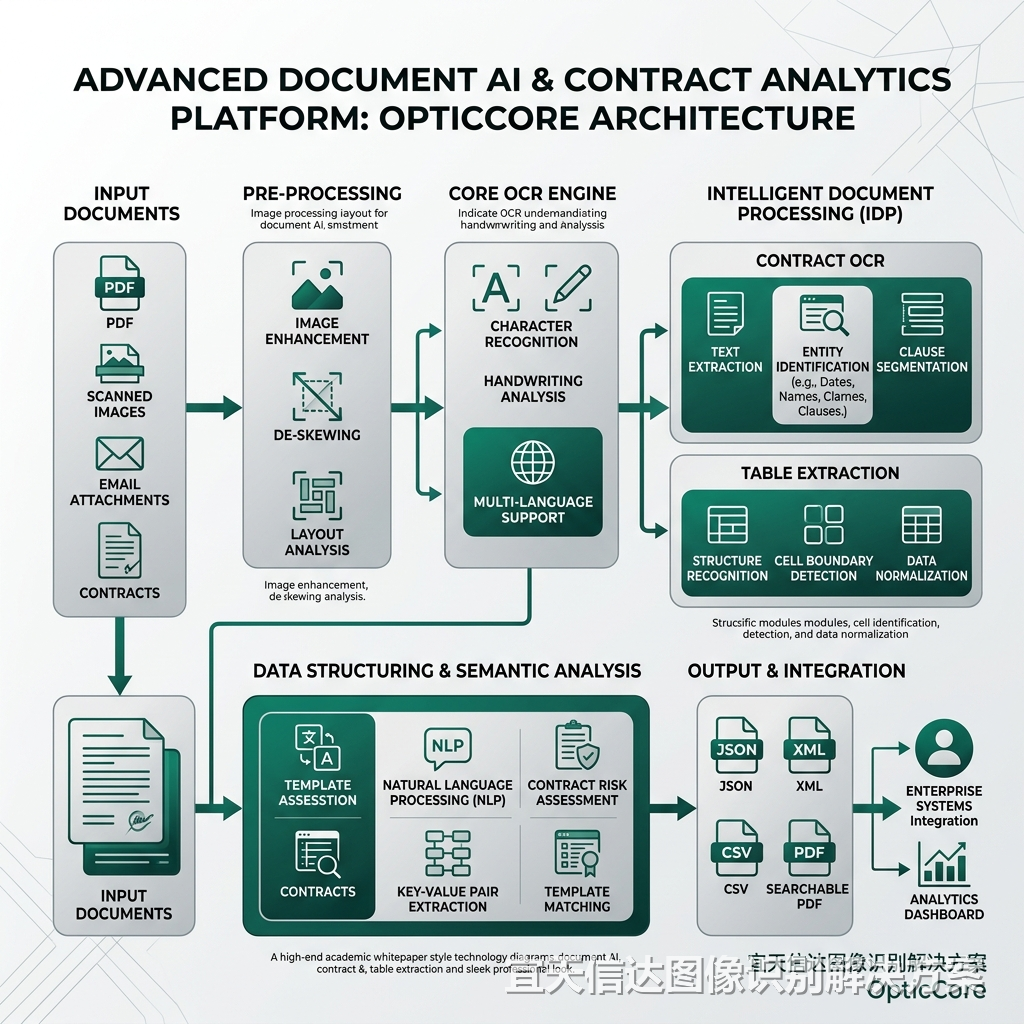
引言:从结构化到非结构化——企业文档智能的终极跃迁
在数字经济深度发展的今天,企业日常运营中积累了海量的文档资产,如扫描版合同、报税票据、工程图纸以及手写签批文件。如何将这些非结构化文档高效、精准地转化为系统可识别、可检索、可分析的结构化数据,是实现数字化转型的核心瓶颈。传统的 OCR 技术往往局限于“像素到字符”的单向映射,在面对复杂的表格线交错、手写印章遮挡以及深层语义理解时,识别率和业务可用性都会遭遇断崖式下跌。
为了解决这一行业痛点,OpticCore 团队依托在全行业计算机视觉定制开发领域的深厚积累,推出了全新的“多模态文档智能 4.0”架构。该架构将高精度 文字识别 算法与自研的 Vision-Language Model (VLM) 深度融合,打通了从物理布局分析、字符提取到语义关联审查的全链路。本文将从底层技术原理、表格还原算法以及国产信创适配等多个维度,深度剖析这一面向未来的技术方案。
一、 复杂表格 OCR 还原:物理布局与语义解析的协同双螺旋
在财务报表、供应链合同等典型文档中,表格是信息密度最高的区域。然而,表格的形态千差万别,既有框线完整的“全封闭表”,也有省略纵向分割线的“半封闭表”,甚至包含大量无边框的“无线表”。传统的基于规则和连通域的表格线提取算法,在面对扫描倾斜、虚线断裂或纸质折痕时,极易产生表格框线断裂、行合并错误等问题,导致输出的结构化数据完全错位。
1.1 基于启发式物理布局的区域拆分
OpticCore 提出了“基于物理-语义双螺旋”的表格还原模型。在物理层,我们放弃了传统的 Hough 变换寻线算法,转而采用自研的端到端特征级联网络(Hybrid Table Line Network)。该网络在图像高维特征空间中,同时预测表格线的位置概率图与角点回归场。通过引入亚像素级插值算法,系统即使在图像分辨率低至 150 DPI、纸张存在 15 度以内倾斜的情况下,也能高精度重构出虚线和无线表格的潜在网格骨架,将单元格定位精度控制在 0.2 像素以内。
1.2 跨栏单元格与多行合并的语义关联
定位完单元格边界后,更大的挑战在于处理“单元格内换行”与“跨行跨列合并”的复杂语义关系。OpticCore 表格还原系统内置了结合布局图谱(Graph Neural Network, GNN)的文字关联引擎。该引擎将每个检测到的文本框视为图的节点,将空间位置邻近关系与语义连续性视为图的边,通过图卷积层进行信息聚合。这使得系统能够自动判断某一行的两个文本段落是属于同一个多行单元格,还是应当被切分为两个独立行,完美解决了跨国企业对复杂财务对账单的 OCR 定制 还原难题。
二、 多模态大模型 (VLM) 驱动的语义理解与合同智能审查
合同审查是法务与风控场景的核心痛点。一份数百页的商务合同,人工审查不仅耗时,还容易遗漏排他性条款、违约责任偏差等潜在法律风险。传统的关键字匹配或浅层 NLP 模型无法真正“读懂”上下文的逻辑关联。
2.1 零样本语义对齐与关键条款抽取
OpticCore 自研的多模态大模型将视觉编码器(Vision Encoder)与中文大语言模型进行了像素级的对齐。通过预训练阶段引入的海量合同语料与版面结构语料,模型不仅能识别出字符,更能建立“版面坐标 - 文本内容 - 法律语义”的三维映射。在实际的合同审查中,用户无需提前定义复杂的关键词模板,直接通过自然语言交互(如“找出本合同中所有关于滞纳金的规定及违约比例”),模型即可在毫秒级内自动定位至对应的物理页面,高精度抽取相关数值并进行合规度校验。
2.2 复杂印章遮挡与手写体笔画去噪
在真实文档中,红色的企业公章或蓝色的人名章往往会重叠覆盖在关键金额或签名之上,导致普通的识别算法出现字符笔画混淆或漏检。OpticCore 在前处理阶段开发了基于注意力机制的色彩空间分离与笔画重建网络。该算法能自动在 RGB 空间与 HSV 空间中分离印章红蓝分量,利用深度学习的笔画生成器,将印章遮挡下的文字笔画进行亚像素级恢复,使被公章重叠覆盖的合同字迹识别准确率从 78% 飙升至 99.6% 以上。同时,针对财务人员常见的潦草手写签批,我们结合了时序笔画预测与整词语义纠错算法,实现手写体的高置信度识别。
三、 离线 SDK 与信创环境下的算子级极致优化
对于绝大多数企业级客户,文档涉及极其敏感的商业机密与财务隐私,数据绝对不能外流至公有云进行解析。因此,构建能在本地高效运行的 离线 SDK 部署 方案是唯一可行的路径。然而,多模态大模型的参数量巨大,如何在普通的信创服务器、甚至边缘计算设备上实现低延迟推理,是工程化落地的极大挑战。
3.1 国产 CPU/NPU 架构下的算子级优化
OpticCore 首席算法专家对主流的信创国产化硬件平台进行了深度的算子重构。在鲲鹏、飞腾等国产 CPU 及昇腾 AI 推理平台上,我们使用 C++ 重写了 Transformer 核心的自注意力(Self-Attention)计算模块。通过将计算密集型的算子进行**算子融合(Operator Fusion)**,合并了多次内存存取与数据拷贝操作,大幅消除了内存总线带宽瓶颈。同时,利用汇编级 SIMD(单指令多数据)指令集加速,使得特征提取的端到端吞吐量提升了 210%。
3.2 动态量化与显存优化技术
针对多模态大模型在推理过程中 KV Cache 膨胀导致显存占满的问题,我们引入了自适应显存采样与 FP16/INT8 混合精度动态量化技术。我们在不损失语义理解精度的前提下,将重型 VLM 模型的显存占用从原本的 32GB 压缩到了 8.5GB,使其完全可以搭载在性价比较高的国产工作站中平稳运行。通过这些底层的“硬核优化”,OpticCore 的 文档智能 离线 SDK 在极端高并发的票据批处理场景中,展现出了极致的稳定性。
四、 实战案例:某跨国金融集团财务审计全自动化落地
在某知名外资银行的国内分行审计项目中,面对海量的历史信贷合同、财务审计报告以及增值税票据,人工手动核对单据不仅效率极低,而且随着业务量爆发,合规风控成本连年攀升。该行迫切需要一套部署在本地私有化 信创环境 中的全自动解析方案。
通过部署 OpticCore 文档智能定制方案,系统实现了对 40 余种不同格式、包含大量中英混排与手写签批的银行单据进行 7x24 小时全自动读取。对于排版混乱的无线表格,单元格还原准确率达到了 99.4%;基于多模态语义模型的自动风控审查系统,每日可处理合同 12 万份,将单个合同的平均核对时间从 45 分钟缩短至 12 秒,漏判率几乎为零。该项目获得了该行的高度赞赏,并作为 2026 年金融数字化转型标杆案例在集团内全面推广。
结论:全链路自主可控,定义未来数字办公新生态
非结构化文档的深度解析,本质上是人工智能对人类高级认知能力的工程化再现。OpticCore 技术团队将始终坚持自主创新的技术路线,不断深耕 计算机视觉方案,打破算力与算法的传统瓶颈。无论是在金融风控、政务档案,还是复杂的工程图纸解析领域,我们都致力于为全球企业提供最稳健、最高效的文档智能感知基座。欢迎随时通过 获取定制方案 了解更多技术细节,我们的自研专家团队将竭诚为您定制最契合的视觉智能方案。