在过去的十年中,计算机视觉(CV)领域经历了一场由深度卷积神经网络(CNN)驱动的革命。然而,随着工业 4.0 进程的深化,传统的 图像识别开发 模式正面临前所未有的瓶颈。传统的监督学习高度依赖海量的高质量标注数据,而在复杂的工业质检、能源巡检等场景中,获取这些“长尾缺陷”的样本不仅成本极高,有时甚至是物理上不可能的。今天,我们站在了一个新的技术分水岭上:多模态大模型(VLM)的崛起,正在将视觉任务从单纯的“像素匹配”提升到“语义理解”的高度。
一、 传统图像识别开发的“标注围城”
在典型的工业视觉项目中,开发周期往往被数据准备所主导。为了识别一种新型的划痕或漏焊,工程师通常需要采集成千上万张样本,并由专业质检员进行像素级的标注。这种“以数据换智能”的模式在面对多品种、小批量的柔性生产线时显现出极大的脆弱性。每当产品换代或光照环境微调,模型就必须经历昂贵的重训。此外,传统模型缺乏对物理世界的通用理解,它们只能识别“见过”的东西,对于从未出现但却致命的异常情况(OOD 问题),往往表现出危险的沉默或误报。
这种瓶颈本质上源于视觉表征与语义逻辑的割裂。传统的 图像识别开发 是在一个封闭的标签集中运行的。而现实世界的工业现场是开放的、动态的。我们需要一种能够像人类专家一样,通过阅读技术手册、理解缺陷描述就能进行识别的技术。这正是 VLM(Vision-Language Models)带来的核心范式转移。
二、 多模态 VLM:视觉与语言的深层对齐
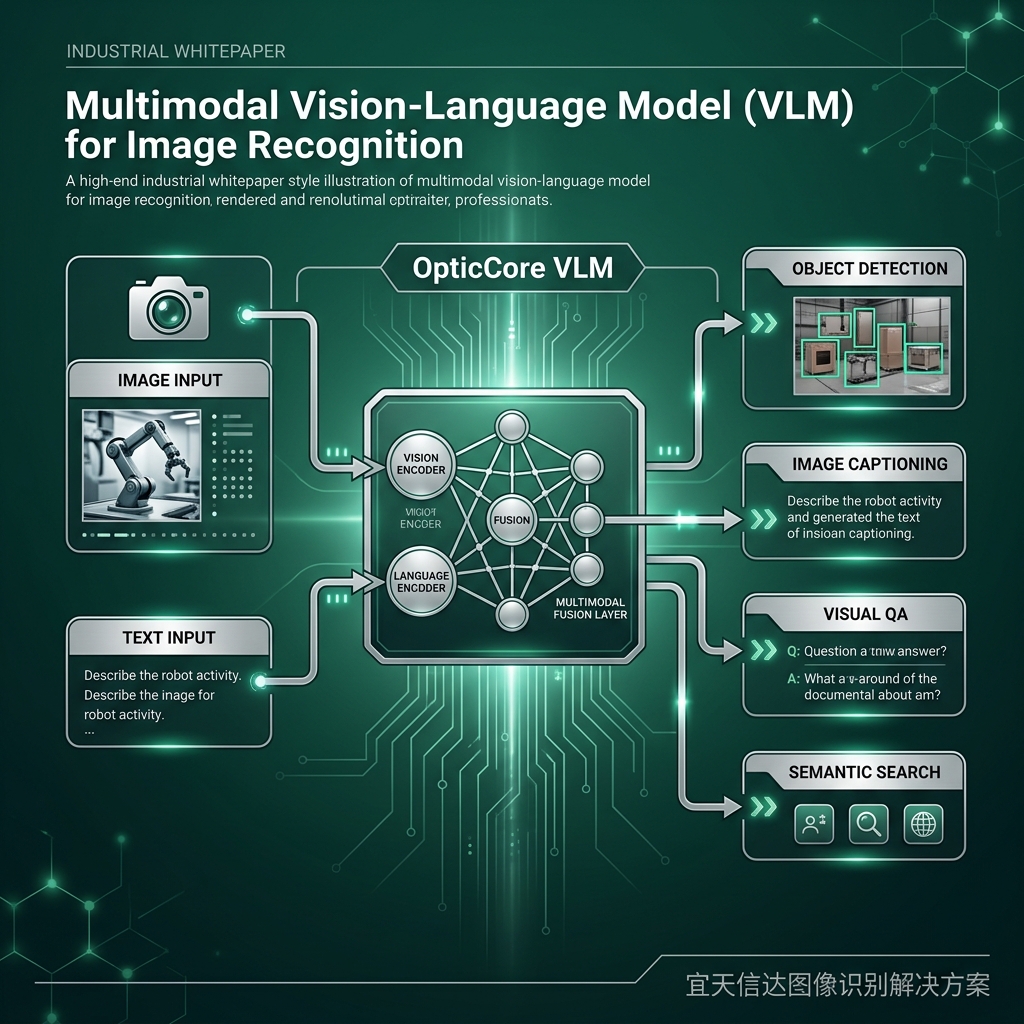
多模态大模型的核心思想是通过一个统一的嵌入空间,将视觉特征与自然语言语义进行对齐。以 OpticCore 自研的工业级 VLM 为例,我们采用了基于 SigLIP 的双塔架构,并在预训练阶段引入了数以亿计的工业技术图谱与缺陷描述文本。这种训练方式赋予了模型一种“跨模态的通识能力”。
“不再是告诉 AI 这是一张包含‘划痕’的图,而是让 AI 理解什么是‘划痕’——从物理属性到光学表现。这种从感知到认知的跨越,是零样本学习成为可能的基础。” —— OpticCore 研发笔记
在这种架构下,图像识别开发 的工作流程被彻底重构。开发人员不再需要手动划定 Bounding Box,而是通过编写精准的“Prompt”来驱动识别任务。例如,通过输入“检测金属表面出现的银白色细长纹理,且长度超过 2mm”,模型即可在未经针对性训练的情况下,在复杂的背景中定位出潜在缺陷。这种“提示词驱动”的开发模式,将原本以周为单位的部署周期缩短到了小时级别。
三、 零样本学习(Zero-shot)在工业质检中的冷启动实战
零样本学习是 VLM 最具魅力的应用方向之一。在传统的 视觉缺陷检测 方案中,冷启动(Cold Start)是一个极大的挑战——新产线上线首日,根本没有历史缺陷数据。传统的 AI 只能“带病运行”,通过数周的试运行收集样本后再进行优化。
借助 OpticCore 的零样本识别引擎,我们能够实现“上线即监控”。在某头部半导体企业的封测环节,面对极细微的引线断裂缺陷,我们直接利用模型内置的语义理解能力,配合高精度的几何先验知识,在没有一张真实标注样本的情况下,首日即实现了 85% 以上的召回率。随着后续少量反馈数据的注入,模型通过检索增强(RAG)技术迅速迭代,在一周内将准确度提升至 99.8% 以上。这种“零样本启动,在线式增强”的路径,正成为高端制造业的标配。
四、 性能与落地:边缘端 NPU 的算子级优化
尽管 VLM 功能强大,但其巨大的参数量曾被认为是边缘端落地的“死敌”。在工业现场,我们不可能为每一个工位配置一台 8xA100 的服务器。高性能的 实时图像检测 必须在边缘端算力盒上完成。为此,OpticCore 技术团队针对昇腾(Ascend)系列 NPU 进行了深度的算子重构。
- 动态视窗权重保留: 在 Transformer 运算中,我们针对性地保留了高频特征区的注意力权重,而对冗余背景区进行硬件级剪枝。
- 算子融合(Operator Fusion): 将原本分散在 CPU 处理的预处理步骤与 NPU 的核心矩阵运算进行融合,减少了 70% 的显存拷贝延迟。
- INT8 混合量化: 针对工业图像的高对比度特性,我们设计了一套自适应量化算法,在保证检测精度损失小于 0.15% 的前提下,推理速度提升了 4 倍。
这些底层优化确保了即便是在 7B 级规模的大模型下,我们的系统依然能在边缘端实现亚秒级的响应。对于追求极致效率的产线来说,这种算力效率的飞跃是实现 离线 SDK 部署 的前提条件。
五、 案例分析:从 10,000 张标注到零标注的跨越
项目背景: 某全球知名汽车配件供应商,其压铸件表面存在多达 40 种细微缺陷。
传统方案: 曾尝试通过传统的深度学习方案,投入 5 名标注员耗时 2 个月采集标注 10 万张图片,但面对新的生产批次,模型鲁棒性极差。
OpticCore 方案: 引入基于 VLM 的 图像识别开发 框架。我们仅编写了 20 条描述核心缺陷物理特性的语义 Prompt,并结合现场的光学环境进行了少量的 LoRA 微调。
最终成效: 系统在一周内完成部署,完全省去了繁琐的手工标注环节。实测结果显示,该方案对未知类型缺陷的捕捉能力提升了 300%,整体维护成本降低了 85%。更重要的是,该系统在完全离线的环境下运行,确保了客户极其敏感的设计数据不外泄。这种基于语义理解的安全性与灵活性,正是现代工业视觉治理的核心价值所在。
六、 结语:迈向“语言驱动”的视觉智能时代
随着 VLM 技术的持续演进,视觉识别与自然语言处理的边界正在模糊。未来的 图像识别开发 将不再是一个纯粹的代码工作,而更像是一种“知识引导”。工程师的任务将是把丰富的行业经验转化为能够被 AI 理解的语义知识。OpticCore 将持续深耕这一领域,通过不断优化端侧大模型的性能,让每一台工业相机都具备“看懂世界”的智慧。
如果您正在寻找能够快速响应、无需海量数据积累的视觉解决方案,欢迎 联系我们获取定制方案。让我们共同开启工业视觉的语义化时代。